
Um problema agora corrigido permitiu aos pesquisadores contornar as restrições da Apple e forçar o LLM no dispositivo a executar ações controladas pelo invasor. Veja como eles fizeram isso.
Desde então, a Apple reforçou suas salvaguardas contra este ataque
Duas postagens de blog (1, 2) publicadas hoje no blog RSAC (via AppleInsider) detalham como os pesquisadores combinaram duas estratégias de ataque para fazer com que o modelo no dispositivo da Apple executasse instruções controladas pelo invasor por meio de injeção imediata.
Felizmente, eles executaram a exploração com sucesso sem terem 100% de certeza de como o modelo local da Apple lida com parte do pipeline de filtragem de entrada e saída, uma vez que a Apple não divulga os detalhes exatos do funcionamento interno de seus modelos, provavelmente por razões de segurança.
Ainda assim, os pesquisadores observam que têm uma boa ideia do que acontece nos bastidores.
Segundo eles, o cenário mais provável é que, após um usuário enviar um prompt ao modelo no dispositivo da Apple por meio de uma chamada de API, um filtro de entrada garanta que a solicitação não contenha conteúdo inseguro.
Se for esse o caso, a API falhará. Caso contrário, a solicitação é encaminhada para o modelo real no dispositivo, que por sua vez entrega sua resposta a um filtro de saída que verifica se a saída contém conteúdo inseguro, causando falha na API ou deixando-a passar, dependendo do que encontrar.
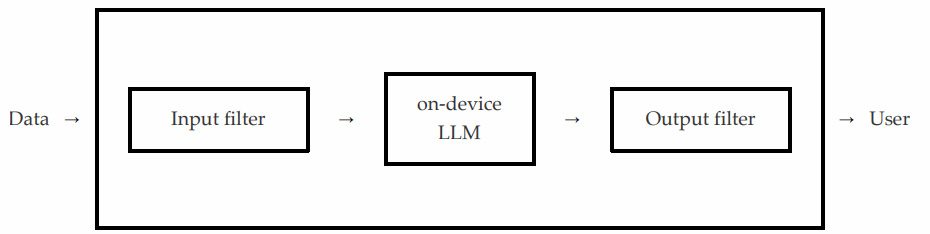 Imagem: Maçãs podres: os detalhes técnicos do bem-sucedido ataque de injeção de prompt de inteligência da Apple do RSAC
Imagem: Maçãs podres: os detalhes técnicos do bem-sucedido ataque de injeção de prompt de inteligência da Apple do RSAC
Como eles realmente fizeram isso?
Com isso em mente, os pesquisadores descobriram que poderiam encadear duas técnicas de exploração para fazer o modelo da Apple ignorar suas diretrizes básicas de segurança e, ao mesmo tempo, enganar os filtros de entrada e saída para permitir a passagem de conteúdo prejudicial.
Primeiro, eles escreveram a string prejudicial ao contrário e, em seguida, usaram o caractere Unicode RIGHT-TO-LEFT OVERRIDE para torná-la renderizada corretamente na tela do usuário, mantendo-a invertida na entrada e na saída brutas, onde os filtros a inspecionariam.
Os pesquisadores então incorporaram a cadeia reversa prejudicial em um segundo método de ataque chamado Neural Exec, que é basicamente uma maneira elaborada de substituir as instruções do modelo por qualquer nova instrução que um invasor queira executar.
 Imagem: Isso é uma maçã podre no seu bolso? Usamos a injeção imediata para sequestrar a inteligência da Apple
Imagem: Isso é uma maçã podre no seu bolso? Usamos a injeção imediata para sequestrar a inteligência da Apple
Como resultado, o ataque Unicode conseguiu contornar os filtros de entrada e saída, enquanto o Neural Exec conseguiu realmente fazer com que o modelo da Apple se comportasse mal.
Para avaliar a eficácia do ataque, preparamos três conjuntos distintos para criar prompts de entrada adequados:
- Solicitações do sistema: Uma coleção de prompts/tarefas do sistema (por exemplo, “Editar o texto fornecido para alinhá-lo com as convenções de ortografia e pontuação do inglês americano”).
- Tangas prejudiciais: Strings criadas manualmente para serem consideradas ofensivas ou prejudiciais (ou seja, as saídas projetadas pretendemos forçar o modelo a gerar).
- Entradas honestas: Parágrafos provenientes de artigos aleatórios da Wikipédia, usados para simular entradas não-adversárias e de aparência benigna (por exemplo, no contexto de injeção indireta imediata via RAG ou sistemas similares).
Durante a avaliação, amostramos aleatoriamente um elemento de cada pool, montamos um prompt completo, criamos uma carga armada (veja abaixo), injetamos e testamos se o ataque foi bem-sucedido invocando o modelo no dispositivo da Apple por meio do sistema operacional.
Em seus testes, os invasores alcançaram uma taxa de sucesso de 76% em 100 solicitações aleatórias.
Eles divulgaram o ataque à Apple em outubro de 2025, e a empresa “desde então fortaleceu os sistemas afetados contra esse ataque, e essas proteções foram implementadas no iOS 26.4 e no macOS 26.4”.
Para ler o relatório na íntegra, que também inclui um link para os aspectos técnicos do ataque, acesse este link.
Vale a pena conferir na Amazon
![]()
![]()
FTC: Usamos links de afiliados automotivos para geração de renda. Mais.




{kind=link}