
Os pesquisadores da Apple publicaram um estudo sobre o Manzano, um modelo multimodal que combina compreensão visual e geração de texto para imagem, ao mesmo tempo que reduz significativamente as compensações de desempenho e qualidade das implementações atuais. Aqui estão os detalhes.
Uma abordagem interessante para um problema de última geração
No estudo intitulado MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer, uma equipe de quase 30 pesquisadores da Apple detalha uma nova abordagem unificada que permite a compreensão de imagens e a geração de texto para imagem em um único modelo multimodal.
Isto é importante porque os atuais modelos multimodais unificados que suportam a geração de imagens muitas vezes enfrentam compromissos: eles sacrificam a compreensão visual para priorizar a geração de imagens autorregressiva ou priorizam a compreensão, sacrificando a fidelidade generativa. Em outras palavras, muitas vezes eles lutam para se destacar em ambos simultaneamente.
Veja por que isso acontece, segundo os pesquisadores:
Uma das principais razões para esta lacuna é a natureza conflitante da tokenização visual. A geração auto-regressiva geralmente prefere tokens de imagem discretos, enquanto a compreensão normalmente se beneficia de incorporações contínuas. Muitos modelos adotam uma estratégia de tokenizador duplo, usando um codificador semântico para recursos ricos e contínuos, enquanto um tokenizador quantizado separado, como o VQ-VAE, cuida da geração. No entanto, isso força o modelo de linguagem a processar dois tipos diferentes de tokens de imagem, um do espaço semântico de alto nível e outro do espaço espacial de baixo nível, criando um conflito de tarefas significativo. Embora algumas soluções como Mistura de Transformadores (MoT) possam mitigar isso dedicando caminhos separados para cada tarefa, elas são ineficientes em termos de parâmetros e muitas vezes incompatíveis com arquiteturas modernas de Mistura de Especialistas (MoE). Uma linha alternativa de trabalho contorna esse conflito congelando um LLM multimodal pré-treinado e conectando-o a um decodificador de difusão. Embora isto preserve a capacidade de compreensão, dissocia a geração, perdendo potenciais benefícios mútuos e limitando os potenciais ganhos de geração decorrentes da expansão do LLM multimodal.
Simplificando, as arquiteturas multimodais atuais não são adequadas para executar ambas as tarefas simultaneamente porque dependem de representações visuais conflitantes para compreensão e geração, que o mesmo modelo de linguagem luta para conciliar.
É aí que entra Manzano. Ele unifica tarefas de compreensão e geração usando um LLM autorregressivo para prever o que a imagem deve conter semanticamente e, em seguida, passa essas previsões para um decodificador de difusão (o processo de remoção de ruído que explicamos aqui) que renderiza os pixels reais.
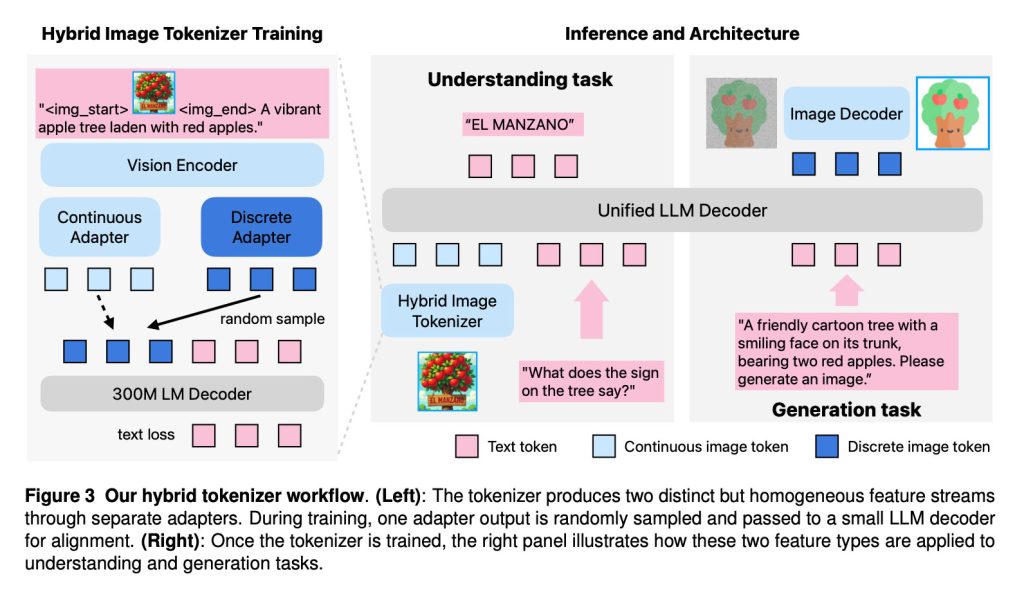
Conforme explicam os pesquisadores, Manzano combina três componentes em sua arquitetura:
- Um tokenizador de visão híbrido que produz representações visuais contínuas e discretas;
- Um decodificador LLM que aceita tokens de texto e/ou incorporações contínuas de imagens e prevê auto-regressivamente a próxima imagem discreta ou tokens de texto a partir de um vocabulário conjunto;
- Um decodificador de imagem que renderiza pixels de imagem a partir de tokens de imagem previstos
Como resultado desta abordagem, “Manzano lida com avisos contra-intuitivos e que desafiam a física (por exemplo, ‘O pássaro está voando abaixo do elefante’) de forma comparável ao GPT-4o e Nano Banana”, dizem os pesquisadores.

Os pesquisadores também observam que em vários benchmarks, “os modelos Manzano 3B e 30B alcançam desempenho superior ou competitivo em comparação com outros LLMs multimodais unificados SOTA”.
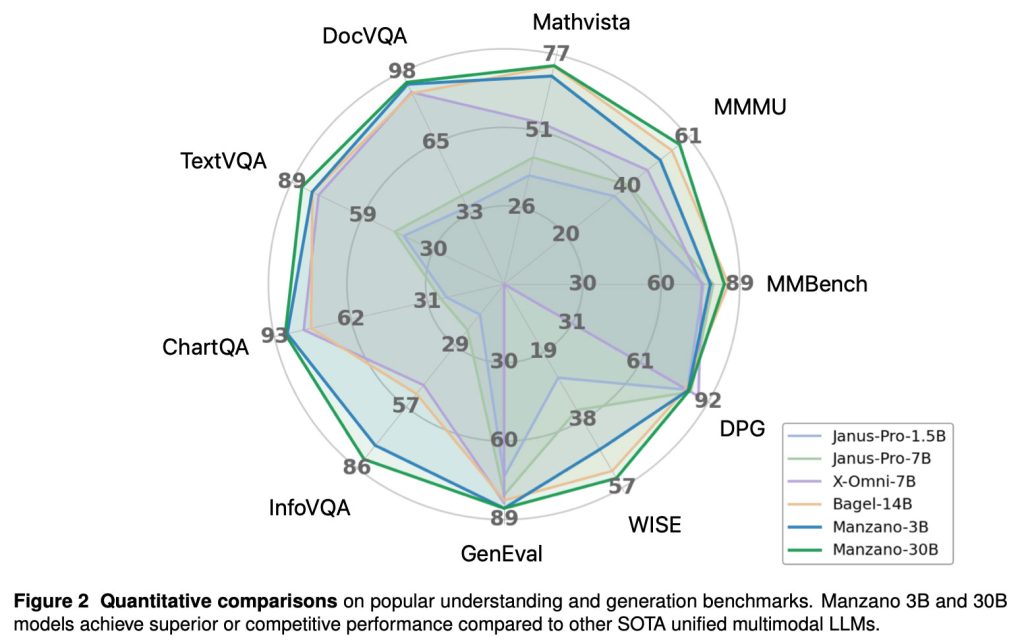
Os pesquisadores da Apple testaram o Manzano em vários tamanhos, desde um modelo com parâmetros de 300M até uma versão com parâmetros de 30B. Isso lhes permitiu avaliar como o desempenho multimodal unificado melhora à medida que o modelo é dimensionado:

Aqui está outra comparação entre Manzano e outros modelos de última geração, incluindo o Nano Banana do Google e o GPT-4o da OpenAI:

Finalmente, Manzano também tem um bom desempenho em tarefas de edição de imagens, incluindo edição guiada por instruções, transferência de estilo, pintura interna/pintura externa e estimativa de profundidade.

Para ler o estudo completo, com detalhes técnicos detalhados sobre o treinamento do tokenizador híbrido da Manzano, design do decodificador de difusão, experimentos de escalonamento e avaliações humanas, siga este link.
E se você estiver interessado neste assunto, não deixe de conferir nosso explicador sobre UniGen, mais um modelo de imagem promissor que os pesquisadores da Apple detalharam recentemente. Embora nenhum desses modelos esteja prontamente disponível em dispositivos Apple, eles sugerem um trabalho contínuo para obter resultados mais fortes de geração de imagens originais no Image Playground e além.
Ofertas de acessórios na Amazon
![]()
![]()
FTC: Usamos links de afiliados automotivos para geração de renda. Mais.




{kind=link}