
Em um novo estudo, um grupo de pesquisadores da Apple descreve uma abordagem muito interessante que adotou, em essência, para obter um modelo de código aberto para ensinar -se a construir boas interfaces rápidas. Aqui está como eles fizeram
No artigo do Uicoder: grandes modelos de idiomas para gerar código de interface do usuário por meio de feedback automatizado, os pesquisadores explicam que, embora o LLM tenha melhorado em várias atividades de escrita, incluindo escrita e codificação criativas, eles ainda lutam para “gerar o código sintatto-corporatório de maneira confiável e bem projetada para a UE”. Eles também têm uma boa ideia de porquê:
Mesmo nos conjuntos de resolvidos ou cuidados manualmente dos finais, os exemplos do código da interface do usuário são extremamente raros; em alguns casos, eles constituem menos de um por cento dos exemplos gerais nos conjuntos de dados de código.
Para enfrentar isso, eles começaram com o Starchat-beta, um LLM de código aberto especializado em codificação. Eles deram a ele uma lista de descrições da interface do usuário e o contrataram para gerar um enorme conjunto de programas SWIFTTI a partir dessas descrições.
Portanto, eles executaram cada peça de código através de um compilador rápido para garantir que ele realmente foi trabalhado, seguido por uma análise GPT-4V, um modelo de linguagem visual que comparou a interface compilada com a descrição original.
Quaisquer saídas que não preencheram, pareciam irrelevantes ou duplicadas, foram lançadas. Os resultados restantes constituíam um conjunto de treinamento de alta qualidade, que foi usado para aperfeiçoar o modelo.

Eles repetiram esse processo várias vezes e notaram que, a cada iteração, o modelo aprimorado gerou um código SWIFT melhor do que antes. Isso, por sua vez, inseriu um conjunto de dados ainda mais limpo.
Após cinco rodadas, eles tinham quase um milhão de programas Swiftui (996.000 para serem mais precisos) e um modelo que chamam de Uicoders, que constantemente compilam e interfaces de produtos muito mais próximos das instruções do que o modelo inicial.

De fato, de acordo com seus testes, o Uicoder superpertou significativamente o modelo básico de código básico em métricas automatizadas e avaliações humanas.
O Uicoder também abordou a correspondência do GPT-4 na qualidade geral e realmente passou na taxa de sucesso da compilação.

Aqui está o kicker: o conjunto de dados original excluiu acidentalmente o código Swiftui
Um dos fatos mais interessantes do estudo veio de uma leve ruína. O modelo original de Starchat-beta foi treinado principalmente em três dados corporativos:
- O TheStack, um grande conjunto de bancos de dados (token de 250b) de repositórios de código autorizados com permissivamente;
- Páginas da web despojadas;
- OpenStant-Walanco, um pequeno conjunto de dados de insulto para instruções.
O problema, como os pesquisadores da Apple explicaram:
Em particular, os dados de treinamento do Storchat-beta contêm alguns dados SWIFT ou nenhum. Os repositórios de código SWIFT foram excluídos por acaso durante a criação dos conjuntos de dados da thestack e, após a inspeção manual, descobrimos que o conjunto de dados OpenStant-Guanaco contém apenas um exemplo (em dez mil) com qualquer código SWIFT no campo de resposta. Nossa hipótese é que quaisquer exemplos rápidos vistos pelo Starchat-beta durante o treinamento provavelmente venham de páginas da web despojadas, que provavelmente são de qualidade inferior e menos estruturada do código do repositório.
Isso significa que os ganhos do Uicoder não são derivados do simples reabastecimento de exemplos de Swiftui que ele já tinha visto (porque quase não havia ninguém em seus dados originais de treinamento), mas nos conjuntos de dados auto-gerados e bem cuidados da Apple criados através do seu ciclo de feedback automatizado.
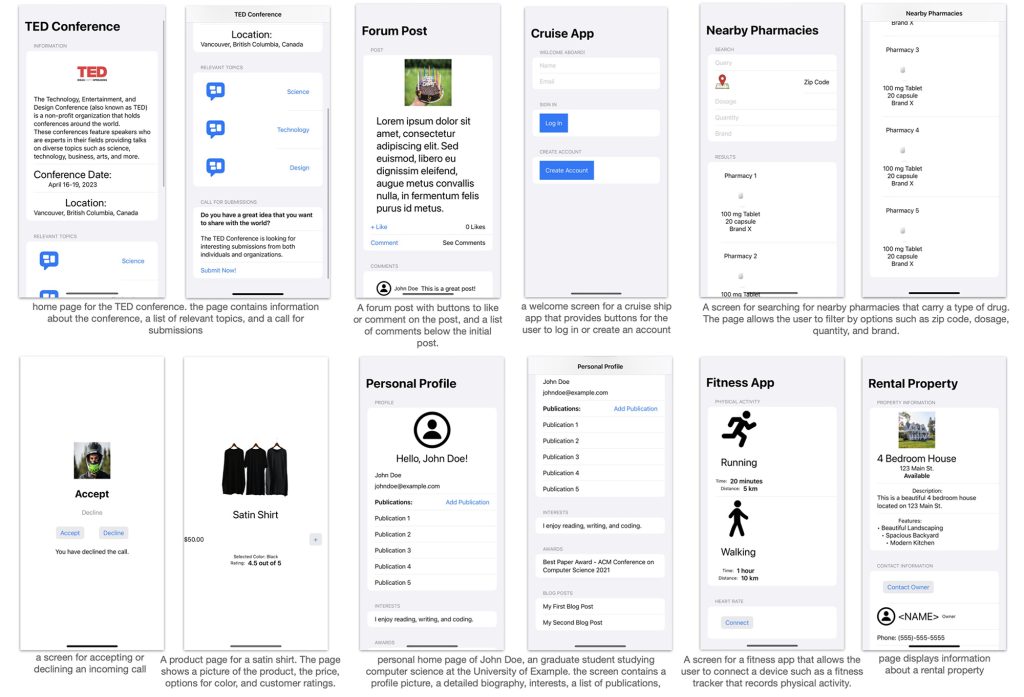 Do estudo: “Captura de tela renderizada pelo código Swiftui gerado por nossos modelos. Para fins ilustrativos, temos manualmente
Do estudo: “Captura de tela renderizada pelo código Swiftui gerado por nossos modelos. Para fins ilustrativos, temos manualmente
Incluindo fotos e ícones de estoque. O código gerado pelo modelo não foi alterado de forma alguma, exceto para atualizar a imagem
Nomes de recursos. ”
Na verdade, isso levou os pesquisadores a supor que, mesmo que seu método tenha se mostrado eficaz na implementação da interface do usuário usando Swiftui, “provavelmente seria generalizado para outros idiomas e o kit de ferramentas da interface do usuário”, o que também é bastante bonito.
O estudo, Uicoder: grandes modelos de idiomas para gerar código de interface do usuário por meio de feedback automatizado, está disponível no ARXIV.
Ofertas do Apple Watch de tempo limitado na Amazon
FTC: Usamos conexões de afiliação automática para obter renda. Além disso.




{kind=link}