
Um grupo de pesquisadores da Apple e da Universidade de Tel-Aviv descobriu uma maneira de acelerar a geração de texto para fala baseada em IA sem sacrificar a inteligibilidade. Veja como eles fizeram isso.
Uma nova abordagem interessante para gerar fala mais rapidamente
Em um novo artigo intitulado Aceitação de granulação grossa com princípios para decodificação especulativa na fala, os pesquisadores da Apple detalham uma abordagem interessante para gerar fala a partir de texto.
Embora existam atualmente várias abordagens para gerar fala a partir de texto, os pesquisadores se concentraram em modelos autorregressivos de conversão de texto em fala, que geram tokens de fala, um de cada vez.
Se você já pesquisou como funciona a maioria dos modelos de linguagem grandes, provavelmente está familiarizado com os modelos autorregressivos, que prevêem o próximo token com base em todos os tokens anteriores.
A geração de fala autorregressiva funciona geralmente de maneira semelhante, exceto que os tokens representam pedaços de áudio em vez de palavras ou caracteres.
E embora esta seja uma forma eficiente de gerar fala a partir de texto, esta abordagem também cria um gargalo de processamento, como explicam os pesquisadores da Apple:
No entanto, para LLMs de fala que geram tokens acústicos, a correspondência exata de tokens é excessivamente restritiva: muitos tokens discretos são acusticamente ou semanticamente intercambiáveis, reduzindo as taxas de aceitação e limitando a aceleração.
Em outras palavras, os modelos de discurso autorregressivos podem ser muito rígidos, muitas vezes rejeitando previsões que seriam boas o suficiente, simplesmente porque não correspondem ao token exato que o modelo espera. Isso, por sua vez, retarda tudo.
Digite, granulação grossa com princípios (PCG)
Resumindo, a solução da Apple baseia-se na premissa de que muitos tokens diferentes podem produzir sons quase idênticos.
Com isso em mente, a Apple agrupa tokens de fala que parecem semelhantes, criando uma etapa de verificação mais flexível.
Dito de outra forma, em vez de tratar todos os sons possíveis como completamente distintos, a abordagem da Apple permite que o modelo aceite um token que pertence ao mesmo grupo geral de “semelhança acústica”.
Na verdade, o PCG é composto por dois modelos: um modelo menor que propõe rapidamente tokens de fala e um segundo modelo de juiz maior que verifica se esses tokens se enquadram no grupo acústico correto antes de aceitá-los.
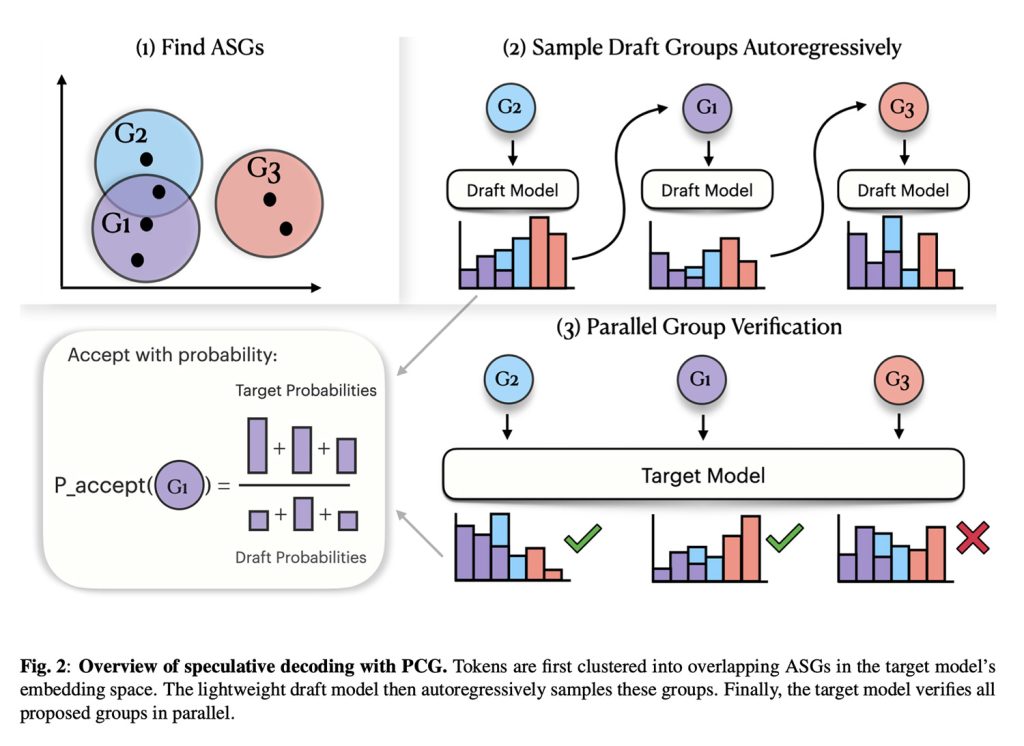
O resultado é uma estrutura que adapta os conceitos de decodificação especulativa (SD) aos LLMs que geram tokens acústicos, o que por sua vez acelera a geração de fala ao mesmo tempo que garante a inteligibilidade.
E por falar em resultados, os investigadores mostram que o PCG aumentou a geração de fala em cerca de 40%, uma melhoria significativa, dado que a aplicação de descodificação especulativa padrão a modelos de fala quase não melhorou a velocidade.
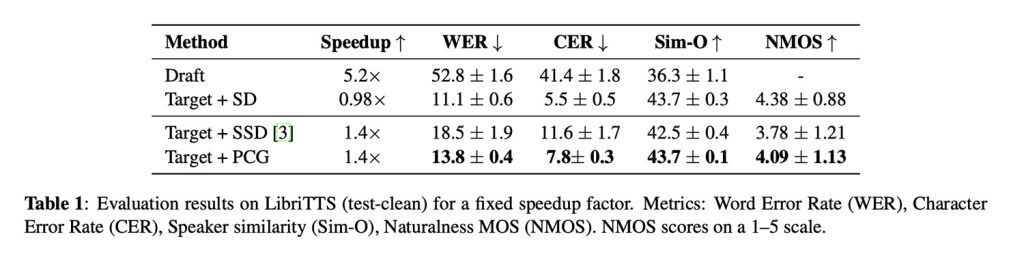
Ao mesmo tempo, o PCG manteve as taxas de erro de palavras em níveis mais baixos do que os métodos anteriores focados na velocidade, preservou a similaridade do locutor e superou as abordagens anteriores focadas na velocidade, alcançando uma pontuação de naturalidade de 4,09 (uma classificação humana padrão de 1 a 5 de quão natural a fala soa).
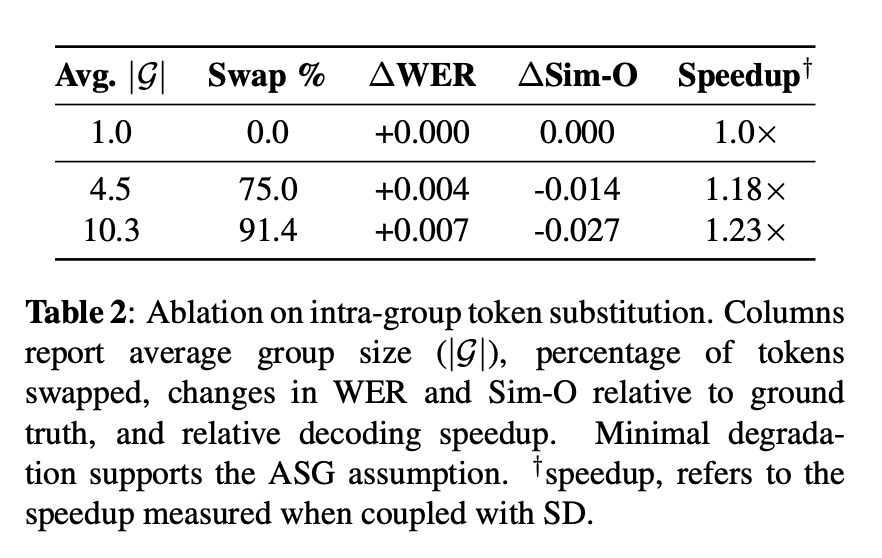
Em um teste de estresse (Ablação na substituição de token intragrupo), os pesquisadores substituíram 91,4% dos tokens de fala por alternativas do mesmo grupo acústico, e o áudio ainda se manteve, com apenas um aumento de +0,007 na taxa de erro de palavras e uma queda de -0,027 na similaridade do locutor:
O que o PCG pode significar na prática
Embora o estudo não discuta o que suas descobertas podem significar na prática para os produtos e plataformas da Apple, esta abordagem pode ser relevante para futuros recursos de voz que precisam equilibrar velocidade, qualidade e eficiência.
É importante ressaltar que esta abordagem não requer o treinamento do modelo de destino, pois é uma mudança no tempo de decodificação. Em outras palavras, é um ajuste que pode ser aplicado aos modelos de fala existentes no momento da inferência, em vez de exigir retreinamento ou alterações arquitetônicas.
Além disso, o PCG requer recursos adicionais mínimos (apenas cerca de 37 MB de memória para armazenar os grupos de similaridade acústica), tornando-o prático para implantação em dispositivos com memória limitada.
Para saber mais sobre o PCG, incluindo detalhes técnicos detalhados sobre conjuntos de dados e contexto adicional sobre os métodos de avaliação, siga este link.
Ofertas de acessórios na Amazon
![]()
![]()
FTC: Usamos links de afiliados automotivos para geração de renda. Mais.
